March 18, 2016
I know this may be annoying but embedding D3 in Pelican isn't the easiest thing so PLEASE click here to see the actual D3! The rest of the blog here will detail the process.
Also, yes very soon I will actually deploy these things somewhere so they aren't just static HTML pages...
But still, hope you enjoy!
What are we doing here
I would like to provide some details both for whoever is reading and also for myself so I remember this project.
This particular project was one of the most difficult to date for me because it required the use of a couple different technologies in unison and also with this project, I tried to actually build most of the D3 visualizations by myself. As a result, it took a bit of time and I am quite proud of the outcome!
The objectives of this project:
- Use MongoDB to store some semi-structured data (namely text data)
- Perform some form of natural language processing over the collected data
- Present the results in an interesting way
The broader goal was to see if I could analyze text and see how presidents' were either similar or different in the topics that they discussed. I also wanted to identify if those topics changed across time.
MongoDB
MongoDB is really easy to get running. Remember that post about the census data? Well let me just post a little bit of code to show how quick it is to set up MongoDB (granted, this is on my local machine and not on AWS...but still I'm trying to make a point so forgive me).
# install with homebrew (mac)
brew install mongodb
# make a data directory (for mongo to write to)
sudo mkdir /data/db
# change ownership for the directory and start the mongo server
sudo chown your_username /data/db
mongod
Boom. After this you can just mongoimport entire .json files into your database as different collections or however you'd like. So all of that to say that it is definitely easier to get things set up and data into the database (not to say that SQL isn't good...they are good for different things).
With the database set up, I had to get my data.
Presidential Data
There were a couple sites that had some great resources, but the one that I ended up using was the UC Santa Barbara American Presidency Project. It has speeches, press releases, and much more dating back to President Washington.

While it would have been great to have some form of an API to make calls to and get nicely formatted data, I did not have that luxury in this case and so I scraped the data that I needed using BeautifulSoup. Usually, this wouldn't be the easiest part, but this time it was actually quite simple!
# make the request to the website
def requester(url):
'''
url: url of the site to be scraped
return: BeautifulSoup obejct of the scraped text
'''
response = requests.get(url)
if response.ok:
return BeautifulSoup(response.text)
# state of the union addresses urls
def get_union_address_url(url):
data = requester(url)
# only extract the links from the page that link to speeches
a = data.find('table').find_all('a', href = re.compile('.*/ws/index'))
speech_urls = []
for link in a:
speech_urls.append(link['href'])
return speech_urls
# extract the text from the speeches as a dictionary
def parse_union_address(url):
data = requester(url)
try:
president, title = data.find('title').text.split(':',1)
except ValueError:
president = ''
title = ''
# create a dictionary with the details of interest
date = datetime.strptime(data.find('span',{'class':'docdate'}).text, '%B %d, %Y')
text = data.find('span',{'class':'displaytext'})
# each paragraph is separated into (as it will be considered a document in later analyses)
text_list = text.find_all(text=True)
text_list = [i.strip() for i in text_list]
aDict = {'president':president.strip(),'title':title.strip(),'date':date,'text':text_list,'url':url,'speech':'State of the Union'}
return aDict
Those three functions above are a sample of the functions that I wrote to scrape the State of the Union Addresses from the website. I had similar functions to scrape Inaugural Addresses and press releases. After getting all the text, I created dictionaries with the details of the speeches and used pymongo to connect to mongoDB so that I could store the data.
It wasn't necessary to use mongoDB because I used Python to scrape the data and was going to manipulate the data in Python,but I wanted to learn how to use the database for future reference. Furthermore, in case anything happened I wouldn't have to rely on the pickled files I created (as an extra saftey measure...).
Network Graph
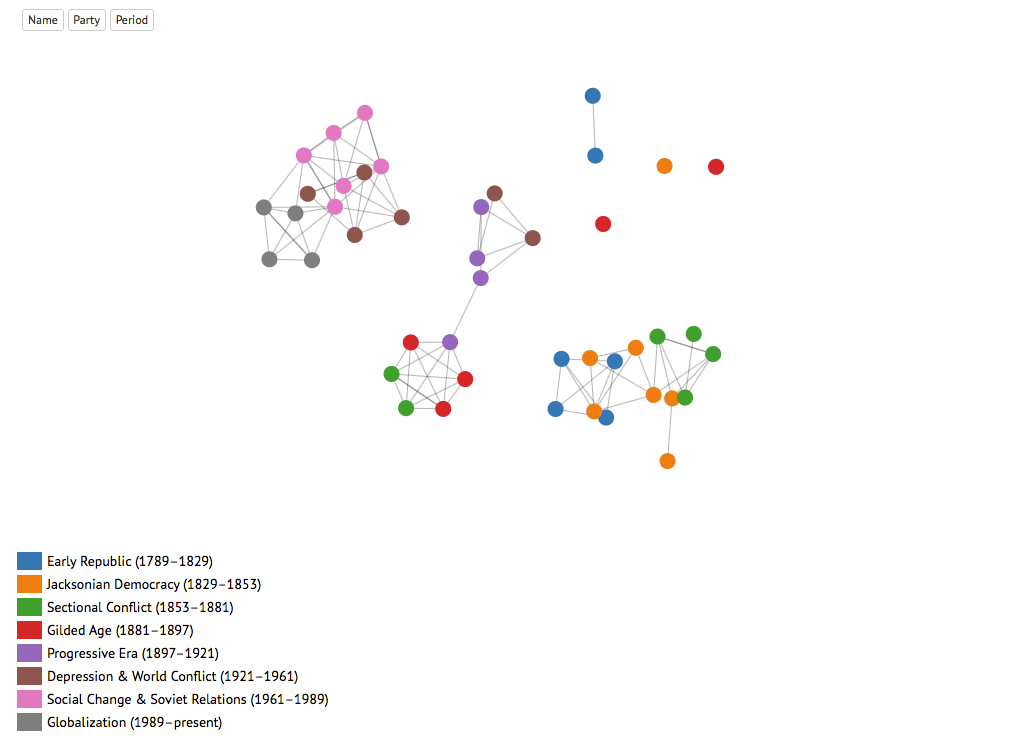
If you took a look at the HTML page that I linked to at the beginning with the network graph of the presidents, you'll notice that there are clusters of presidents. Initially, I hypothesized that the presidents would be clustered by their respective parties; however, I turned out to be really wrong! They were mostly clustered based by the period in which they were president. This makes sense and I will discuss this later.
So how did I generate those clusters? Well, let me start off by talking about how I got to clustering.
Latent Semantic Indexing
One of the interesting techniques that I wanted to use was latent semantic indexing. Very basically, this technique uses matrix factorization (singular value decomposition) to map the documents into a vector space, then we specify the rank (kind of like the number of concepts that we want to keep). Afterwards, the passed in term frequency matrix is factorized into a term concept matrix, a square singular value matrix, and a concept document matrix. The concept document matrix can be thought of as a matrix that captures the latent 'concepts' within the documents.
I used the concept document matrix and computed the cosine similarity between each of the different vectors (in this case each president had his own vector that signified the concepts in his speeches and press releases). Then I created the connections by simply setting the threshold to >= 0.75 (I experimented with this for a bit to see how the connections would turn out; a bit arbitrary, but if I had more time I would have kept all connections and used the weight/width of the connection to represent the cosine similarity).
Taking a Step Back
With the network created, I realized that the connections were actually based more on the time period in which the presidents served. So I added the color and labels to identify the presidents by the period in which they served. I also included the party toggle to show that my initial hypothesis was incorrect.
In order to learn more about what the presidents' talked about, I decided to dive down into the particular time periods. My thought was that if I could limit the president set to within the same time period, then some of the finer details of topics discussed would show up.
Latent Dirichlet Allocation
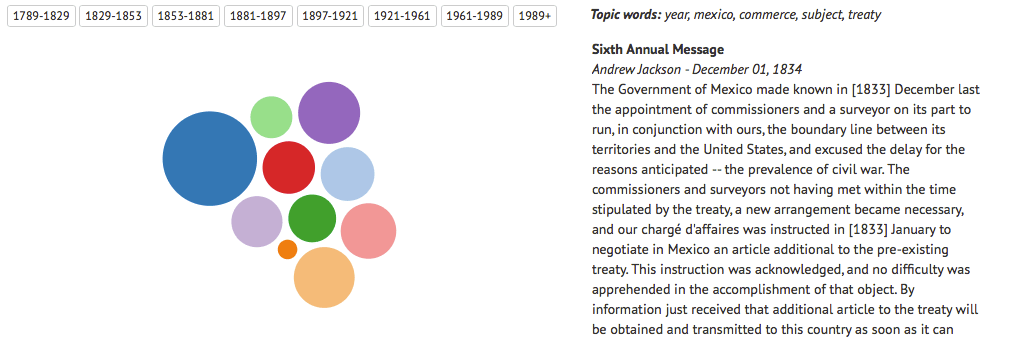
In order to extract the topics that were discussed in the different speeches and press releases, I decided that it would be more accurate to run the analyses on separate paragraphs. When a president gives a State of the Union Address or Inaugural Address, each paragraph is typically a separate topic; therefore, I made each paragraph an individual document (if it was more than 10 words long).
I used latent dirichlet allocation, which is a probabilistic approach to generating topics. Very basically, we start by randomly assigning k topics to a document (a mixture of topics), then each word in the document to a topic. This is a fairly poor representation of the topics at this stage, but it improves by going through and updating the topic for each word by choosing a new topic with probability that the new topic generated this word (here is an awesome explanation that is a lot more clear! Go read! seriously!).
Therefore, for each paragraph I extracted the most likely topic words (from the LDA output). Just to finish things up, I connected these topic words back to the initial paragraphs so that I could see the paragraphs that LDA determined to be a certain topic.
Summary
This project took quite a bit of coordination and also learning because I was trying to use different technologies that I didn't have much experience with. However, it was one of the most fulfilling projects, because by the end I had something that not only summarized the analyses that I performed, but also an interactive demonstration so that others could explore as well.
With that said, there are definitely improvements to be made.
- It isn't long before you notice that some of the initial paragraphs in the scrolling text box are not paragraphs. Instead, there are headers, questions, and other irrelevant forms of text. These should be taken out because they do not really represent paragraphs that the presidents spoke
- As an additional analyses, it would be interesting to run LDA on speeches that aren't State of the Union or Inaugural Addresses because these speeches are typically very broad ranging in topics discussed and therefore each president in the same period of time would most likely be discussing similar matters (think Obama and Bush talking about war...)
Anyways, those are just a few that came to mind. I hope you enjoyed the post and the visualizations!